Chapitre 19 : Algorithme sur les graphes.
Introduction :
Maintenant que vous maîtrisez les bases des graphes, il est temps de plonger dans l'exploration des parcours de graphes et de l'algorithme de Dijkstra. Ces concepts sont essentiels pour résoudre des problèmes complexes et optimiser des processus dans divers domaines.
-
Pourquoi Étudier les Parcours de Graphes ?
Les parcours de graphes, comme le parcours en profondeur (DFS) et le parcours en largeur (BFS), sont des outils puissants pour explorer et analyser des structures de données. Ils permettent de :
- Découvrir des chemins entre différents sommets.
- Détecter des cycles dans un graphe.
- Identifier des composantes connexes pour comprendre la structure d'un réseau.
-
L'Algorithme de Dijkstra : Une Révolution pour les Chemins Optimaux
L'algorithme de Dijkstra va encore plus loin en trouvant le chemin le plus court entre un sommet source et tous les autres sommets dans un graphe pondéré.

Avant propos :
On fera les exercices dans un nouveau dossier, contenant les fichiers suivants du chapitre graphe :
france.pyqui contient les lignes de code permettant de construire la carte de france.structures.py
1. Parcours en largeur d'un graphe (BFS - Breadth-First Search)
Le parcours en largeur est un algorithme utilisé pour explorer de manière systématique un graphe. Il commence à partir d'un noeud source donné, explore tous les noeuds voisins de ce noeud, puis passe aux voisins de ces voisins, et ainsi de suite. Cette méthode garantit que les noeuds sont visités dans l'ordre de leur distance par rapport au noeud source. L'algorithme BFS est particulièrement utile pour résoudre des problèmes de connectivité, la recherche du chemin le plus court et d'autres problèmes liés aux graphes.
Exemple :
Prenons un exemple simple pour illustrer le fonctionnement de BFS. Imaginons le graphe suivant :

Si nous utilisons BFS à partir du noeud source A, l'ordre de visite des noeuds sera : A, B, C, D. L'algorithme commence par le noeud source A, visite ensuite les noeuds B et C (qui sont les voisins directs de A), puis visite le noeud D, voisin de B.
Applications :
- La recherche du chemin le plus court entre deux noeuds.
- La détection de cycles dans un graphe.
- La modélisation des réseaux sociaux et des relations.
- La résolution de jeux de logique et de casse-tête.
Implémentation :
L'implémentation de l'algorithme BFS nécessite généralement l'utilisation d'une file (queue). Voici un exemple en pseudo-code :
BFS(graphe, noeud_de_départ):
file = File()
file.enfiler(noeud_de_départ)
Marquer noeud_de_départ comme visité
Tant que la file n est pas vide:
noeud_actuel = file.defiler()
Traiter noeud_actuel
Pour chaque voisin du noeud_actuel dans le graphe:
Si il est non visité:
file.enfiler(voisin)
Marquer voisin comme visitéPoint important à retenir : il faut marquer quand on enfile et non quand on défile.
2. Exercice :
- Programmer en Python la fonction
parcours_largeur(graphe,noeud_depart)qui prend en paramètres un objetgraphede typeGrapheNonOrientePondereet un stringnoeud_depart. Le traitement du noeud sera simplement l'affichage (print) de la valeur associée à chaque noeud rencontré. - Tester cette fonction sur la carte des routes de France avec comme point de départ la ville de Nice.
3. Exercice type bac :
On cherche à lutter contre un virus informatique qui essaie de contourner les protocoles de sécurité en migrant régulièrement vers un autre ordinateur, en choisissant à chaque fois au hasard sa nouvelle cible parmi les ordinateurs accessibles.
On cherche à savoir quels ordinateurs protéger afin de lutter de manière la plus efficace possible avec des ressources limitées.
On considère le réseau informatique suivant, composé de 5 ordinateurs numérotés : 0, 1, 2, 3 et 4.

-
On représente ce réseau informatique par un graphe que l'on stocke sous forme de liste_s de voisins. Compléter la définition de la variable
voisins.voisins = [ [1, 2, 3, 4], [0, 2, 3], [0, 1], [........], [.....]]
On ajoute au réseau actuel un sixième ordinateur, numéroté 5. Cet ordinateur n'est accessible que des ordinateurs numérotés 0 et 2.
- Dessiner le nouveau graphe sur votre cahier.
- Modifier la variable
voisinsafin qu'il corresponde au graphe. -
Écrire la fonction
voisin_alea(voisins, s)qui prend en paramètre un graphevoisinssous forme de listes de voisins et un entiersreprésentant un sommet et qui renvoie un entier représentant un voisin deschoisi aléatoirement.On pourra utiliser la fonction
random.randrange(n)qui renvoie un nombre aléatoire entre 0 inclus etnexclus.
On donne la fonction marche_alea suivante :
def marche_alea(voisins, i, n):
if n==0:
return i
return marche_alea(voisins, voisin_alea(voisins, i), n-1)
- Justifier que la fonction
marche_aleaest une fonction récursive. - Décrire ce que modélise cette fonction, en rapport avec le contexte de l'exercice.
-
Compléter la fonction
simulequi simulen_testsfois le déplacement d'un virus pendantn_pasétapes, démarrant au sommeti, et qui renvoie une liste contenant en positionjle nombre de fois que le virus a terminé son parcours au sommetj, divisé parn_tests.def simule(voisins , i, n_tests, n_pas) : results = [0] * len(voisins) ..... -
L'appel
simule(voisins, 4, 1000, 1000)renvoie la valeur suivante :[0.328, 0.195, 0.18, 0.12, 0.059, 0.118].Déduire de ce résultat l'ordinateur du réseau qu'il est le plus rentable de protéger.
Au début, on suppose que le virus n'est présent que sur un ordinateur. À chaque étape, il contamine tous ses voisins non déjà contaminés. On cherche à savoir combien de temps prend ce virus pour se propager à tout le réseau.
-
Un graphe
voisinsreprésente un réseau, etsreprésente un sommet de départ.Compléter le programme suivant pour déterminer le temps, en étape, que met un virus à se propager à l'intégralité du réseau.
def nb_etapes_contamination_totale(voisins, s): nb_etapes=0 contamination=[False] * len(voisins) # aucun ordinateur n'est infecté contamination[s]=True # l'ordinateur s devient contaminé while ............................... : #Plusieurs lignes return nb_etapesOn pourra tester notre code sur ce graphe plus grand :

voisins_nombreux = [ [1, 2, 3, 4] , [0, 2, 3, 8, 10] , [0, 1, 5, 6] , [0, 1, 9, 12] , [0, 6, 7] , [2, 13, 27] , [2, 4, 7, 14] , [4, 6, 15, 28] , [1, 25] , [3, 26] , [1, 16, 29] , [12, 17] , [3, 11, 18, 30] , [5, 19] , [6, 20] , [7, 21] , [10, 22] , [11, 23] , [12, 24] , [13] , [14] , [15] , [16] , [17, 24] , [18, 23] , [8] , [9] , [5] , [7] , [10] , [12] ]
4. Parcours en profondeur d'un graphe (DFS - Depth-First Search)
Le parcours en profondeur est un algorithme utilisé pour explorer de manière systématique un graphe en suivant une branche jusqu'à ce qu'il atteigne un noeud terminal, puis il revient en arrière pour explorer d'autres branches. L'algorithme DFS est largement utilisé pour la recherche de chemins, la détection de cycles et d'autres problèmes liés aux graphes.
Exemple :
Prenons un exemple simple pour illustrer le fonctionnement de DFS. Imaginons le graphe suivant :
Si nous utilisons DFS à partir du noeud source A, l'ordre de visite des noeuds pourrait être : A, B, D, C. L'algorithme commence par le noeud source A, explore le noeud B, puis explore le noeud D, avant de revenir au noeud C.
Applications :
- La recherche de chemins dans un graphe.
- La détection de cycles dans un graphe.
- La génération de l'arbre couvrant minimal.
Implémentation :
Il y a deux implémentations possibles : une récursive et l'autre itérative.
-
Récursive :
Voici comment cela pourrait être implémenté en pseudo-code :
DFS(graphe, noeud_actuel, liste_noeud_visite): marquer noeud_actuel comme visité en l'ajoutant à la liste Traiter noeud_actuel Pour chaque voisin du noeud_actuel dans le graphe: Si noeud_actuel n est pas visite: DFS(graphe, voisin, liste_noeud_visite) -
Itérative :
Voici comment cela pourrait être implémenté en pseudo-code :
DFS(graphe, noeud_de_départ): pile = Pile() pile.empiler(noeud_de_départ) On marque le noeud de départ comme étant visité Tant que la pile n est pas vide: noeud_actuel = pile.depiler() Traiter noeud_actuel Pour chaque voisin du noeud_actuel dans le graphe: Si voisin est non visité: pile.empiler(voisin) On marque voisin comme étant visité
5. Exercice :
- Programmer en Python la fonction
parcours_profondeur(graphe,noeud_depart)qui prend en paramètres un objetgraphede typeGrapheNonOrientePondereet un stringnoeud_depart. Le traitement du noeud sera simplement l'affichage (print) de la valeur associée à chaque noeud rencontré. - Tester cette fonction sur la carte des routes de France avec comme point de départ la ville de Nice.
6. Exercice type bac:
Nous avons représenté sous la forme d’un graphe les liens entre cinq différents sites Web :

La valeur de chaque arête représente le nombre de citations (de liens hypertextes) d’un site vers un autre. Ainsi, le site site4 contient 6 liens hypertextes qui renvoient vers le site site5.
Les sites sont représentés par des objets de la classe Site dont le code est
partiellement donné ci-dessous. La complétion de la méthode calcul_popularite fera
l’objet d’une question ultérieure.
class Site:
def __init__(self, nom):
self.nom = nom
self.predecesseurs = []
self.successeurs = []
self.popularite = 0
self.couleur = 'blanche'
def calcul_popularite(self):
pass # sera complété plus tardLe graphe précédent peut alors être représenté ainsi :
# Description du graphe
s1, s2, s3, s4, s5 = Site('site1'), Site('site2'), Site('site3'), Site('site4'), Site('site5')
s1.successeurs = [(s3,3), (s4,1), (s5,3)]
s2.successeurs = [(s1,4), (s3,5), (s4,2)]
s3.successeurs = [(s5, 3)]
s4.successeurs = [(s1,2), (s5,6)]
s5.successeurs = [(s3,4)]
s1.predecesseurs = [(s2,4), (s4,2)]
s2.predecesseurs = []
s3.predecesseurs = [(s1,3), (s2,5), (s5,4)]
s4.predecesseurs = ...
s5.predecesseurs = ...- Sur votre cahier, expliquer la ligne
s2.predecesseurs = []. - Compléter les deux dernières lignes.
- Sur votre cahier, expliquer le contenu
s2.successeurs[1][1].
Pour mesurer la pertinence d’un site, on commence par lui attribuer un nombre appelé valeur de popularité qui correspond au nombre de fois qu’il est cité dans les autres sites, c’est-à-dire le nombre de liens hypertextes qui renvoient sur lui. Par exemple, la valeur de popularité du site site4 est 3.
- Quelle est la valeur de la popularité du site 1 ?
- Compléter le code de la méthode
calcul_popularitede la classeSitequi affecte à l’attributpopularitela valeur de popularité correspondante et renvoie cet attribut.
Afin de calculer cette valeur de popularité pour chacun des sites, nous allons faire un
parcours dans le graphe de façon à exécuter la méthode calcul_popularite pour
chacun des objets.
Voici le code de la fonction qui permet le parcours du graphe :
def parcours_graphe(sommet_depart):
parcours = []
sommet_depart.couleur = 'noire'
liste_s = []
liste_s.append(sommet_depart)
while len(liste_s) != 0:
site = liste_s.pop(0)
site.calcul_popularite()
parcours.append(site)
for successeur in site.successeurs:
if successeur[0].couleur == 'blanche':
successeur[0].couleur = 'noire'
liste_s.append( successeur[0] )
return parcoursDans ce parcours, les sites non encore traités sont de couleur 'blanche' (valeur par
défaut à la création de l’objet) et ceux qui sont traités de couleur 'noire'.
-
Dans ce parcours, on manipule la liste Python nommée
liste_suniquement à l’aide d’appels de la formeliste_s.append(sommet)etliste_s.pop(0).Donner la structure de données correspondant à ces manipulations.
- Donner le nom de ce parcours de graphe en justifiant.
-
La fonction
parcours_grapherenvoie une listeparcours. Indiquer la valeur renvoyée par l’appel de fonctionparcours_graphe(s1)
On cherche maintenant le site le plus populaire, celui dont la valeur de popularité est la plus grande.
Voici le code de la fonction qui renvoie le site le plus populaire, elle prend comme
argument une liste non vide contenant des instances de la classe Site.
def le_plus_populaire(liste_sites):
max_popularite = 0
site_le_plus_populaire=liste_sites[0]
for site in liste_sites:
if site.popularite > max_popularite:
...
...
return site_le_plus_populaire- Compléter la fonction ci-dessus.
- Expliquer ce que renvoie
le_plus_populaire(parcours_graphe(s1)).nom - On envisage d’utiliser l’ensemble des fonctions proposées ci-dessus pour rechercher le site le plus populaire parmi un très grand nombre de sites (quelques milliers de sites). Expliquer si ce code est adapté à une telle quantité de sites à traiter. Justifier votre réponse.
7. Algorithme de Dijkstra:
L'algorithme de Dijkstra est une méthode utilisée pour trouver le chemin le plus court entre un noeud source et tous les autres noeuds dans un graphe pondéré, c'est-à-dire un graphe où les arêtes ont des poids. Cet algorithme est largement utilisé dans des domaines tels que la planification de trajets, la conception de réseaux et la gestion de projets.
Exemple :
Prenons un exemple simple pour illustrer le fonctionnement de l'algorithme de Dijkstra. Imaginons le graphe suivant :

Si nous utilisons Dijkstra à partir du noeud source A, nous trouverons les distances minimales vers tous les autres noeuds : A(0), B(2), C(5), D(1), E(6). L'algorithme commence par le noeud source A, explore les voisins B et D, puis continue à minimiser les distances aux autres noeuds.
Applications :
- La recherche du chemin le plus court dans les réseaux routiers.
- La planification de trajets dans la logistique et les transports.
- La conception de réseaux de télécommunication.
- La gestion de projets pour identifier les chemins critiques.
8. Exercice:
A faire dans le cahier.
On considère le graphe ci-dessous :
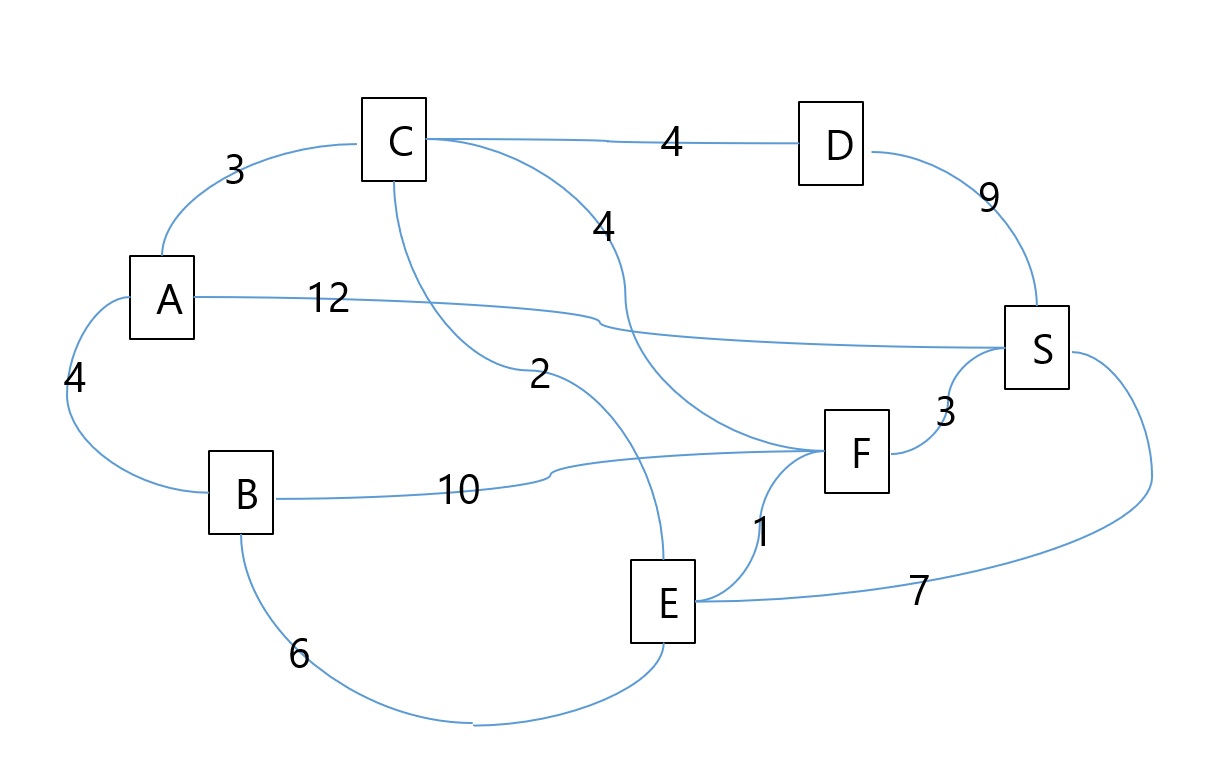
Déterminer à l'aide d'un papier et d'un stylo le plus court chemin entre A et S.
9. Implémentation de l'algorithme de Dijkstra
L'implémentation de l'algorithme de Dijkstra nécessite généralement l'utilisation de structures de données telles qu'une file de priorité ou un tas binaire pour maintenir les noeuds non visités avec les distances minimales. Vous pouvez le coder en utilisant votre langage de programmation préféré. Voici un exemple en pseudo-code :
dijkstra(graphe, noeud_de_départ,noeud_arrivee):
Initialiser une table de distances avec des distances infinies pour tous les noeuds.
Initialiser une table des noeuds visités en mettant Faux à tous les noeuds.
Initialiser une table des prédécesseurs vide pour l ensemble des noeuds
Mettre la distance du noeud_de_départ à 0.
Mettre le noeud actuel comme étant le noeud de départ.
Mettre le noeud de départ comme étant visité
Tant que le noeud_arrivee n est pas visité:
Pour chaque voisin non visité du noeud actuel:
Calculer la distance temporaire à partir du noeud_de_départ
Si cette distance temporaire est plus courte que la distance enregistrée dans la table, mettre à jour la distance et le prédecesseur de ce noeud
Sélectionner le noeud non visité avec la plus petite distance.
Marquer ce noeud comme visité.
Mettre ce noeud comme noeud actuel
Retourner la table des prédécesseurs.10. Exercice:
-
Compléterl'algorithme de Dijkstra en Python qui prend 3 paramètres : le graphe, le sommet de départ et le sommet d'arrivée. Cette fonction retournera le dictionnaire associant à chaque sommet son prédecesseur afin de former le chemin le plus court entre le noeud le sommet de départ et le sommet d'arrivée.
import os os.chdir("u:\\terminaleNSI") # à modifier si nécessaire import france import structures import math routes=france.routes def dijkstra(graphe,noeud_depart,noeud_arrivee): #Initialiser une table de distances avec des distances infinies pour tous les noeuds. #Initialiser une table des noeuds visités en mettant Faux à tous les noeuds. #Initialiser une table des prédécesseurs vide pour l ensemble des noeuds dico_distances = {} dico_visites = {} dico_predecesseurs = {} for noeud in graphe.liste_sommets(): dico_distances[noeud] = math.inf dico_visites[noeud] = False dico_predecesseurs[noeud] = "" - Tester avec
france.routes -
Ecrire la fonction
chemin_le_plus_court(graphe, noeud_depart, noeud_arrivee)qui renvoie la liste des noeuds traversés formant le chemin le plus court entrenoeud_depart,noeud_arrivee.Par exemple :
>>> chemin_le_plus_court(france.routes, "Nice", "Marseille") ["Nice", "Cannes", "Le Luc", "Brignoles", "Aix-en-Provence", "Marseille"]
On testera ce programme à l'aide de l'exercice sur les routes du chapitre précédent.
11. Exercice:
Le but de l'exercice est de réfléchir à la recherche de cycle pour les graphes orientés.
Dans la suite de l'exercice, nous appelerons "cycle" tous les chemins dont les points qui le compose sont distincts à l'exception du point de départ et d'arrivée qui sont identiques.
Considérons le code suivant :
def parcours_profondeur(graphe, sommet_depart):
chemins = []
def dfs(chemin):
dernier = chemin[-1]
if dernier in graphe:
for voisin in graphe[dernier]:
deja_dans_chemin = False
for s in chemin:
if s == voisin:
deja_dans_chemin = True
if not deja_dans_chemin:
nouveau_chemin = chemin + [voisin]
chemins.append(nouveau_chemin)
dfs(nouveau_chemin)
dfs([sommet_depart])
return chemins
def recherche_de_cycle(graphe, sommet_depart):
tous_les_chemins = parcours_profondeur(graphe, sommet_depart)
cycles = []
for chemin in tous_les_chemins:
pass
pass
pass
# a completer
return cycles
# Exemple de graphe orienté pour tester
graphe_test = {
"A": ["B", "C"],
"B": ["C", "D"],
"C": ["A"],
"D": ["E"],
"E": ["B"]
}
# Tests
print("Tous les chemins à partir de A :")
for chemin in parcours_profondeur(graphe_test, "A"):
print(chemin)
'''
print("\nTous les cycles à partir de A :")
for cycle in recherche_de_cycle(graphe_test, "A"):
print(cycle)
'''
Das
- Tracer le graphe donné à titre d'exemple dans le code Python sur votre cahier.
- Y a-t-il des cycles à partir de A? Combien? Lesquels?
- Que fait la première fonction?
- Compléter la deuxième fonction afin de chercher des cycles.
12. Exercice :
Ecrire la fonction villes_proches(graphe, ville_depart, distance) qui renvoie une liste de toutes
les villes qui sont à un temps inférieur ou égal de ville_depart. 🤯